
Wer länger mit Agenten arbeitet, kennt den Frust: Sobald man das Tool wechselt, fühlt es sich an, als würde das Gedächtnis des Systems wieder bei null starten.
CLAUDE.md, .cursorrules, .windsurfrules, AGENTS.md, verschiedene Hook-Mechanismen, verschiedene Rechte-Modelle, verschiedene Dateinamen. Viel Arbeit landet in tool-spezifischer Konfiguration statt in portablem Wissen.
Genau hier setzt codejunkie99/agentic-stack an. Die Kernidee ist simpel und stark: one brain, many harnesses. Mit Harness ist hier die jeweilige Laufumgebung gemeint (z. B. Claude Code, Cursor oder Windsurf), also die Schicht, die Modelle, Tools und Regeln im konkreten Editor/CLI zusammenbindet. Nicht jedes Tool soll schlau sein, sondern der gemeinsame .agent/-Ordner.
Das Problem: Jede Harness spricht einen anderen Dialekt
Heute ist der Wechsel zwischen Agent-Tools oft teuer:
- Regeln und Prompts müssen neu strukturiert werden
- Hooks funktionieren je nach Harness anders oder gar nicht
- Team-Konventionen werden in Nischen-Dateien eingeschlossen
Das führt zu einem klassischen Lock-in auf Konfigurationsebene. Agentic Stack dreht das um: Das Wissen lebt in .agent/; die Harness wird zur Adapter-Schicht.
Die Architektur: Drei Module, ein Prinzip
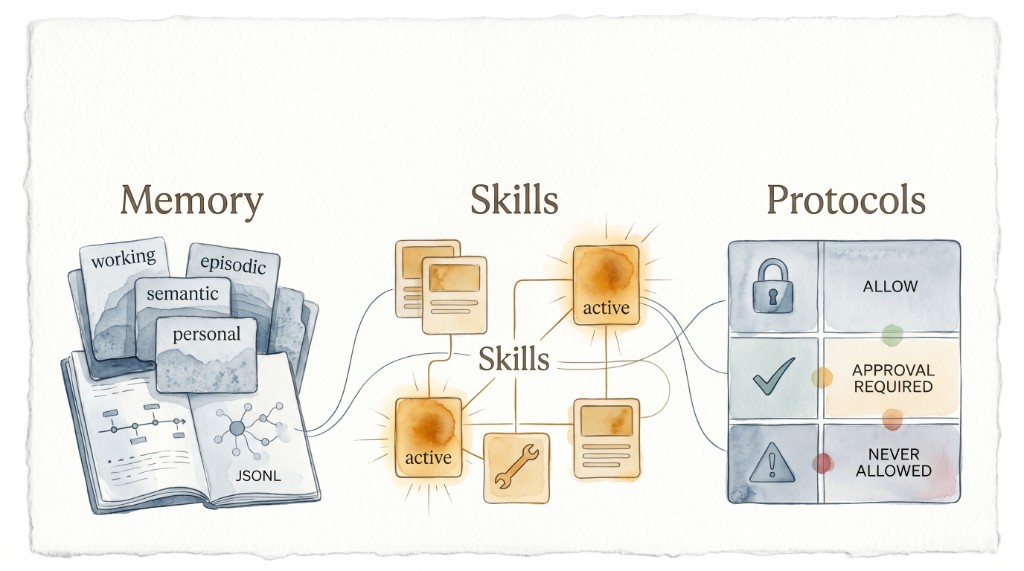
Der Ansatz trennt sauber zwischen Memory, Skills und Protocols.
1) Memory: Vier Schichten statt ein Kontext-Blob
Das Gedächtnis ist in Ebenen mit unterschiedlicher Halbwertszeit organisiert:
working/: aktueller Task-Zustand, flüchtigepisodic/: vergangene Durchläufe als JSONL, inkl. Salience-Scoresemantic/: verdichtete Muster, die mehrere Episoden überdauernpersonal/: benutzerspezifische Präferenzen
Wichtiger Architekturentscheid: personal/ wird nicht in semantic/ eingeschmolzen. Persönliche Eigenheiten eines Entwicklers sollen nicht zum globalen Weltwissen des Agenten werden.
2) Skills: Progressive Disclosure statt Alles-auf-einmal
Im Standardkontext liegen nur zwei kleine Dateien:
_index.md(welche Skills existieren)_manifest.jsonl(Trigger: Keywords, Dateimuster, Kontexte)
Die vollständige SKILL.md wird erst geladen, wenn der Task passt. Das schont Token-Budget und hält den Arbeitskontext sauber.
Die Seed-Skills im Repo sind gut gewählt:
skillforgememory-managergit-proxydebug-investigatordeploy-checklist
Spannend: Skills können sich über Self-Rewrite-Hooks selbst zur Überarbeitung markieren, wenn sie wiederholt scheitern. Lernen passiert damit als nachvollziehbarer Diff in Git statt als Black-Box-Effekt.
3) Protocols: Harte Grenzen statt Prompt-Wunschliste
Der dritte Teil regelt, was der Agent tun darf:
permissions.mdmitallow/approval-required/never-allowedtool_schemas/mit getypten Tool-Interfacesdelegation.mdfür Sub-Agent-Regeln
Gerade im Homelab- und Infra-Bereich ist das zentral: Wer SSH, CI/CD oder Ansible über Agenten steuert, braucht harte Verbote, nicht weich formulierte Hinweise.
Adapter-Schicht: Einmal Wissen, viele Harnesses
Im adapters/-Ordner sitzt pro Tool ein Shim, der nur den lokalen Dialekt spricht. Die Idee ist immer gleich: tool-spezifische Config zeigt auf .agent/, Wissen bleibt identisch.
Praktische Konsequenz: Toolwechsel bedeutet primär Adapterwechsel, nicht Gedächtnisverlust.
Die eigentliche Stärke: Feedback-Loops
Agentic Stack ist nicht nur Dateiordnung, sondern ein Lernprozess mit mehreren Schleifen:
- Skill-Resultate landen in
episodic/ memory-managerdestilliert Muster nachsemantic/skillforgeschlägt neue Skills für wiederkehrende Lücken vor- Wiederholte Fehler markieren Skills zur Überarbeitung
- Constraint-Verletzungen werden systematisch eskaliert
Dadurch wird git log .agent/memory/ zur nachvollziehbaren Lernhistorie.
Dream Cycle: Konsolidierung um 03:00
Per nächtlichem Cron-Job läuft eine Konsolidierung über alte Episoden:
0 3 * * * cd /path/to/project && python3 .agent/memory/auto_dream.py >> .agent/memory/dream.log 2>&1Das Prinzip ist pragmatisch: Regelmässig verdichten, damit der Kontext nicht ungebremst wächst.
Warum das Muster relevant ist
Drei Punkte stechen heraus:
1) Portabilität zwischen Harnesses
Der Wechsel zwischen Tools wird günstiger, weil das Wissen nicht an Dateikonventionen hängt.
2) Versionierte Selbstmodifikation
Der Agent kann sich verbessern, aber jede Änderung ist reviewbar und revertierbar.
3) Trennung von personal und semantic
Teamwissen bleibt teamfähig; persönliche Präferenzen bleiben persönlich.
Was (noch) fehlt
Als produktionsreifes System fehlen derzeit unter anderem:
- ein stärkeres Evaluations-Framework für Skill-Qualität
- robuste Konfliktlösung für Multi-User-Schreibzugriffe auf Memory
- klarere Story für Skill-Sharing zwischen Projekten
- konsistente Benennung in allen Integrationsdokumenten
Das schmälert den Wert nicht, aber es ist wichtig für die Einordnung: Blueprint statt Endprodukt.
Fazit
Agentic Stack ist einer der saubereren Vorschläge, wie man aus fragmentierten Agent-Setups ein tragbares Betriebssystem für Wissen macht.
Nicht weil alles schon fertig ist, sondern weil das Grundprinzip stimmt:
Die Harness darf wechseln. Das Gehirn bleibt.
Quellen
- Repository: github.com/codejunkie99/agentic-stack
- Lizenz: MIT