
Anyone who has worked with coding agents for a while knows the pattern: the moment you switch tools, your setup suddenly feels amnesic.
CLAUDE.md, .cursorrules, .windsurfrules, AGENTS.md, different hook systems, different permission models, different file conventions. Too much hard-won knowledge gets trapped in tool-specific config.
That is exactly the pain point codejunkie99/agentic-stack tries to solve. The core idea is simple and strong: one brain, many harnesses. Here, harness means the runtime wrapper around the agent (for example Claude Code, Cursor, or Windsurf) that wires models, tools, and rules into a concrete editor/CLI workflow. Keep the harness thin; keep the knowledge in a shared .agent/ directory.
The Problem: Every Harness Speaks a Different Dialect
Today, moving between agent tools is expensive:
- rules and prompts need to be rewritten
- hooks work differently (or not at all) across harnesses
- team conventions get buried in niche config files
That is classic config-level lock-in. Agentic Stack flips it: knowledge lives in .agent/, harnesses become adapters.
The Architecture: Three Modules, One Principle
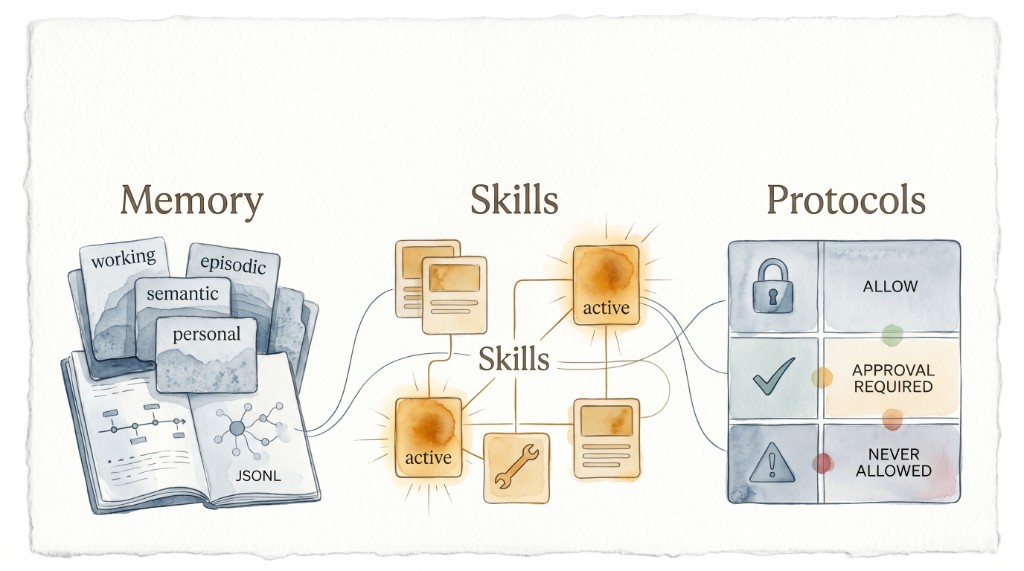
The design separates responsibilities cleanly into Memory, Skills, and Protocols.
1) Memory: Four Layers Instead of One Giant Context Blob
Memory is split by half-life:
working/: current task state, short-livedepisodic/: prior runs in JSONL, with salience scoressemantic/: distilled patterns that survive multiple episodespersonal/: user-specific preferences
Important design choice: personal/ never gets merged into semantic/. One developer’s habits should not silently become the agent’s global worldview.
2) Skills: Progressive Disclosure Instead of Loading Everything
By default, only two small files are always present:
_index.md(what skills exist)_manifest.jsonl(triggers: keywords, file patterns, contexts)
The full SKILL.md is loaded only when triggers match the active task. That is token-budget-friendly and keeps context focused.
The seed skills in the repo are practical:
skillforgememory-managergit-proxydebug-investigatordeploy-checklist
A notable mechanism: self-rewrite hooks. If a skill fails repeatedly, it can mark itself for revision. Learning happens as a visible Git diff, not as hidden model drift.
3) Protocols: Hard Boundaries, Not Prompt Wishes
The third module defines what an agent is allowed to do:
permissions.mdwithallow/approval-required/never-allowedtool_schemas/with typed tool interfacesdelegation.mdfor sub-agent handoff rules
In homelab and infra workflows, this is critical. If agents can touch SSH, CI/CD, or Ansible, you want enforceable boundaries, not polite suggestions.
Adapter Layer: One Knowledge Core, Many Harnesses
The adapters/ directory contains a shim per harness. The pattern is consistent: tool-specific config points to .agent/; the knowledge itself stays unchanged.
Practical outcome: switching tools becomes mostly an adapter task, not a memory reset.
The Real Advantage: Feedback Loops
Agentic Stack is more than a folder structure. It is a learning workflow:
- Skills log outcomes into
episodic/ memory-managerdistills recurring patterns intosemantic/skillforgeproposes new skills for repeated gaps- repeated failures flag skills for revision
- constraint violations escalate systematically
That turns git log .agent/memory/ into a traceable learning history.
Dream Cycle: Consolidation at 03:00
A nightly cron job runs consolidation:
0 3 * * * cd /path/to/project && python3 .agent/memory/auto_dream.py >> .agent/memory/dream.log 2>&1The idea is pragmatic: compress regularly so context size does not grow without bound.
Why This Pattern Matters
Three aspects stand out:
1) Harness portability
Switching tools gets cheaper because knowledge is no longer tied to file conventions.
2) Versioned self-modification
The agent can improve itself, but every change is reviewable and reversible.
3) Strict split between personal and semantic
Team knowledge stays team-safe; individual preferences stay individual.
What Is Still Missing
As a production system, it still lacks parts:
- stronger skill evaluation framework
- robust multi-user conflict handling for shared memory writes
- cleaner cross-project skill sharing model
- fully consistent naming across integration docs
That does not reduce its value, but it frames expectations correctly: blueprint, not finished product.
Conclusion
Agentic Stack is one of the cleaner proposals I have seen for turning fragmented agent setups into a portable operating model for knowledge.
Not because everything is finished, but because the core principle is right:
Harnesses can change. The brain stays.
Sources
- Repository: github.com/codejunkie99/agentic-stack
- License: MIT