
Quand on travaille avec des agents de code, le problème revient vite: on change d’outil, et une partie du savoir opérationnel disparaît.
CLAUDE.md, .cursorrules, .windsurfrules, AGENTS.md: chaque harness a son dialecte.
Ici, harness désigne la couche d’exécution (Cursor, Claude Code, Windsurf, etc.) qui relie modèle, outils et règles dans un workflow concret.
codejunkie99/agentic-stack propose un contre-modèle: one brain, many harnesses.
Le problème: dialectes incompatibles
- règles à réécrire à chaque migration
- hooks différents selon l’outil
- conventions d’équipe enfermées dans des fichiers spécifiques
Agentic Stack inverse la logique: le savoir vit dans .agent/, les outils deviennent de simples adaptateurs.
Architecture: trois modules, un principe
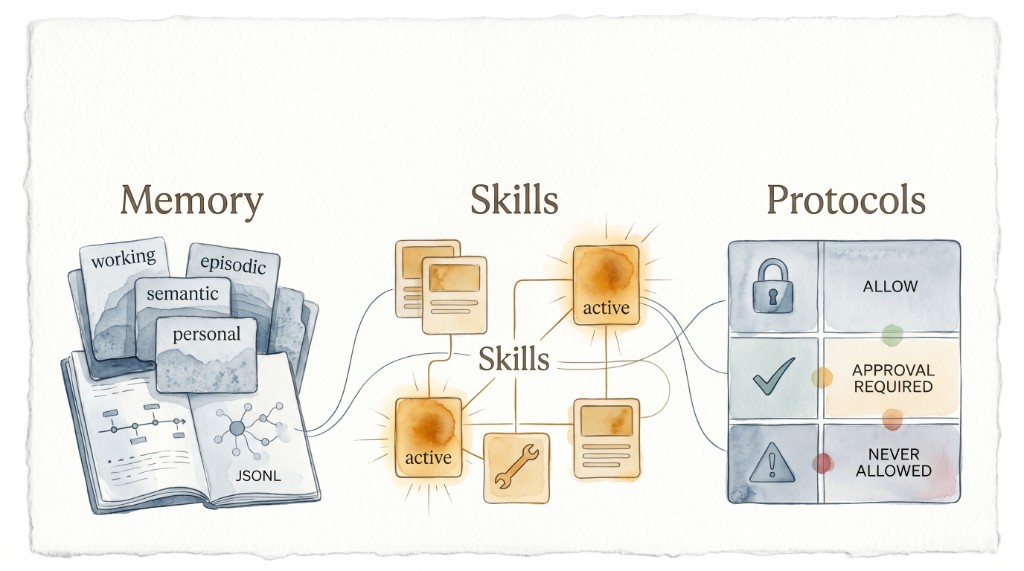
Le design sépare clairement Memory, Skills et Protocols.
1) Memory
Mémoire en quatre couches:
working/(court terme)episodic/(historique JSONL)semantic/(patterns consolidés)personal/(préférences utilisateur)
Point clé: personal/ ne doit pas fusionner dans semantic/.
2) Skills
Progressive disclosure:
_index.mdpour l’inventaire_manifest.jsonlpour les triggers- chargement d’une
SKILL.mdcomplète seulement quand nécessaire
Les seed skills (skillforge, memory-manager, git-proxy, etc.) montrent une bonne direction.
3) Protocols
Frontières d’action explicites:
permissions.md(allow,approval-required,never-allowed)tool_schemas/delegation.md
En infra réelle (SSH, CI/CD, Ansible), des limites dures sont indispensables.
Adapter layer
Le dossier adapters/ traduit le dialecte de chaque harness vers .agent/.
Résultat: changer d’outil coûte moins cher, car le cerveau reste stable.
Boucles d’apprentissage
Le système combine plusieurs loops:
- logs skills ->
episodic/ - consolidation ->
semantic/ - proposition de nouveaux skills
- auto-révision après échecs répétés
- escalade des violations de contraintes
Cela rend l’apprentissage auditable dans Git.
Dream cycle
Consolidation nocturne via cron:
0 3 * * * cd /path/to/project && python3 .agent/memory/auto_dream.py >> .agent/memory/dream.log 2>&1Objectif: compresser régulièrement la mémoire utile sans faire exploser le contexte.
Ce qui manque encore
Le repo est un blueprint prometteur, pas un produit fini:
- évaluation plus robuste de la qualité des skills
- meilleure gestion multi-utilisateur sur mémoire partagée
- partage cross-projets plus propre
- cohérence de naming dans les docs d’intégration
Conclusion
L’idée centrale est solide:
on peut changer de harness, sans perdre le cerveau.
Sources
- Repository: github.com/codejunkie99/agentic-stack
- Licence: MIT